There has been a phenomenon of how to decide if the data is big or not. I’ve seen TBs of image data in terms of size, and GBs of text data in terms of count. Yet, Netflow is whole a different story… For the first time, I felt like operating Nebuchadnezzar as Tank does in the Matrix movie. Please, think about the incoming data of ~1 million customers’ requests, and referrals for a second, and then buckle up to dive into the rabbit hole.

NetFlow is a feature that was introduced on Cisco routers around 1996 that provides the ability to collect IP network traffic as it enters or exits an interface.NetFlow is introduced by Cisco in 1996 to collect IP network traffic as incoming or outgoing.
https://en.wikipedia.org/wiki/NetFlow
We can extract the source/destination of traffic, network protocol, duration, usage in terms of bytes, and some more details from Netflow data. Due to the increasing need, lots of new Netflow versions are released. Nowadays, “Netflow v9/IPFIX” is the most popular one all around the world. While Netflow is designed to work with Cisco routers, IPFIX became a more universal solution and works perfectly for all types of network devices. To see all the fields and representations of IPFIX, please check the IANA’s IPFIX Entities page.
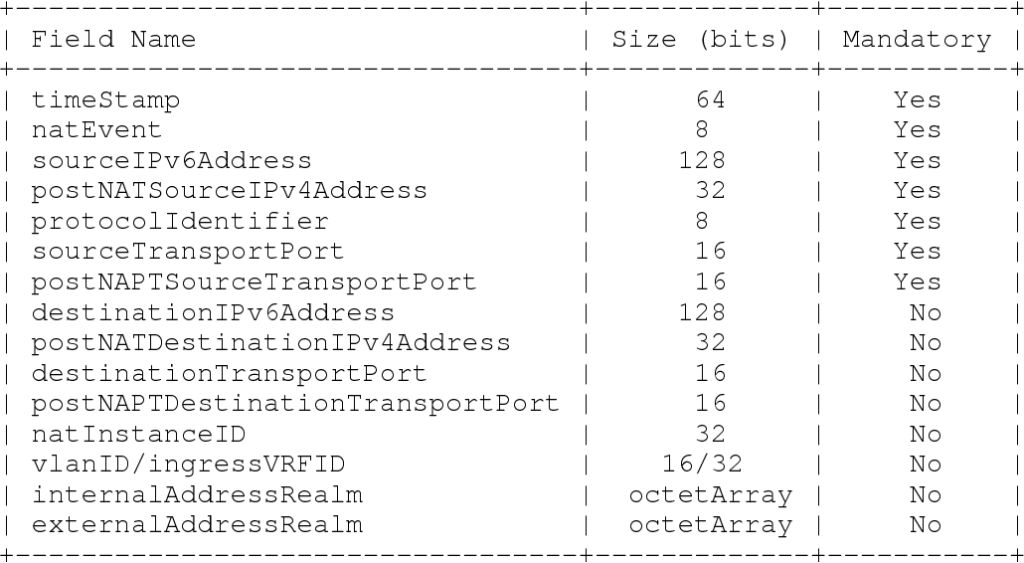
Just before the technical aspect, I’d like to mention CDR data too. Since Netflow contains IP addresses as an identifier, we need to find a way to add usernames for output. This can be done with the help of CDR. CDR tells us which IP address is occupied by which customer in which time range. To sum up, what I need to do is “get the IP address from Netflow, and join CDR by considering traffic direction and time conditions”.
There are lots of open-source and proprietary tools for collecting Netflow data. As you know I’m an open-source volunteer, so my by-default choices became the ones that can be found on GitHub. When I joined the project, nfdump was used. It’s another open-source alternative yet it doesn’t support streaming data architecture (I’ll discuss that in incoming paragraphs) which is crucial to overcome matrix-like incoming data problems. nfdump collects data for given intervals (1 minute, 5 minutes, etc.) and divides it into small packages which require another tool to extract raw data.
To work with a similar aspect, CDR data was requested with intervals too. So, I prepared a benchmark to understand what are the reasons behind the congestion in preparing output data. Benchmark and report indicated working with the quantized data is the main issue. Finally, I realized that changing tools themselves will not save us and we need to make a radical change to adapt streaming data architecture.
The new stack arises with the following tools:
* Goflow2: https://github.com/netsampler/goflow2
* Apache Kafka: https://kafka.apache.org/
* KSQLDB: https://ksqldb.io/
* Freeradius (not in my expertise, but I’ll mention why it’s good)
* of course some magical Python scripts.
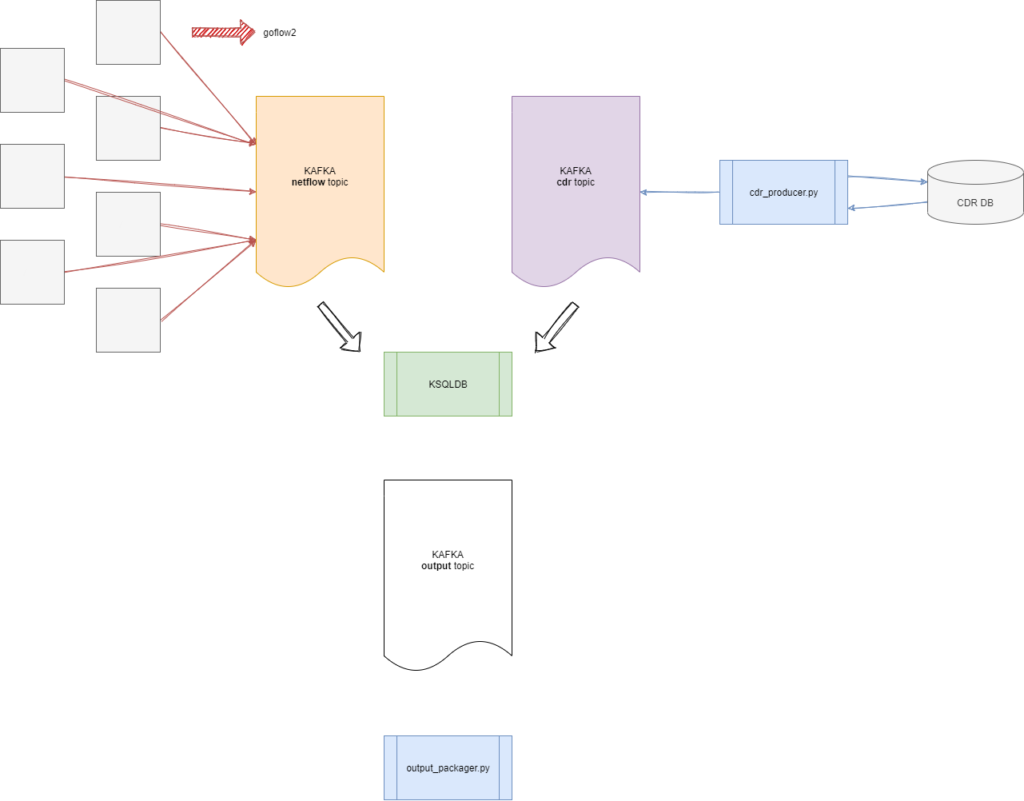
Then, I proposed the architecture above. What I was thinking is basically, keeping the code in that ecosystem minimal and decreasing the need for human intervention to as low as possible. Also, the CDR part is going to be replaced with Freeradius and then we’ll get rid of another code, soon. I’m not the enemy of “codes”, yet I want to be as quick as possible and not to make any more delays. I chose KSQLDB for almost the same reason. KSQLDB helps us to join two Kafka topics just like SQL joins. Despite my first try at such a project, KSQLDB became the hearth of this architecture.
As you can guess, designing such an architecture needs also reliability. All the choices mentioned before have a common feature. They all are scalable. So, you can run as many as goflow2 simultaneously. Just like Kafka and KSQLDB.
Let me introduce you to the stack, one by one. Goflow2 is a fork of Cloudflare’s Goflow project. It’s a Netflow/sFlow/IPFIX collector written via Go language. You can start as many as goflow2 instances in a server. What makes goflow2 a better option among all the other collectors? Transport options of course. You can ship incoming netflow data to lots of tools, such as Kafka, Elasticsearch, etc.
Now, it’s time for most data engineering parts of the architecture.. and those are Kafka and KSQLDB. Kafka stores and redirects data through the topics. It’s probably the most commonly used tool all around the world for streaming data architectures. It’s worth that check it out when you need solutions for “data pipelines”, “streaming analytics” and more. KSQLDB plays a mission-critical role here. You can process Kafka topics in real-time with the native Kafka support and all you need to do is write some SQL queries. It’s super easy to create a new stream for merged data.. just organize your ordinary SQL query “SELECT * FROM” with some “WHERE blah blah” conditions and put “CREATE STREAM” at first.
CREATE STREAM s3 AS
SELECT s1.c1, s2.c2
FROM s1
WHERE s1.c1 > 10
JOIN s2 WITHIN 5 MINUTES
ON s1.c1 = s2.c1 EMIT CHANGES;Previously, we had a pull-based method to get CDR data from accounting servers. As a part of modernization, accounting servers and applications are renewed with Freeradius. Once again I’d like to mention that, I don’t have any experience with those tools or concepts directly. Yet, I’m glad for being able to consume CDR data directly from Kafka topics with the help of some open-source plugins that can ship data on Freeradius to a given Kafka topic.
For logging, health-checking, and garbage collecting purposes I’ve sprinkled some Python scripts all over the architecture. Logging configurations are set to ERROR level and transferred to Elasticsearch just after parsing via Logstash.
To sum up, the architecture and tools mentioned above solved many issues on our side. I bypassed the installation and integration details since they all have pretty user-friendly documentation and also lots of items to configure for specific cases.
Last but not the least, I’ve read lots of papers dating back to the early 2000s about utilizing machine-learning techniques with Netflow data. After successfully deploying the Netflow collector, I turned my face to real-time analytics on data, too.. which will be the topic of the upcoming blog post.
Stay tuned for “A brief data science on Netflow”.